Why Knowledge Graphs Outperform Vector Databases for Accurate AI Analysis
While vector databases have been instrumental in building the LLMs we use today, knowledge graphs fundamentally outperform them for complex AI analysis tasks, particularly when deep understanding of relationships between entities is critical.
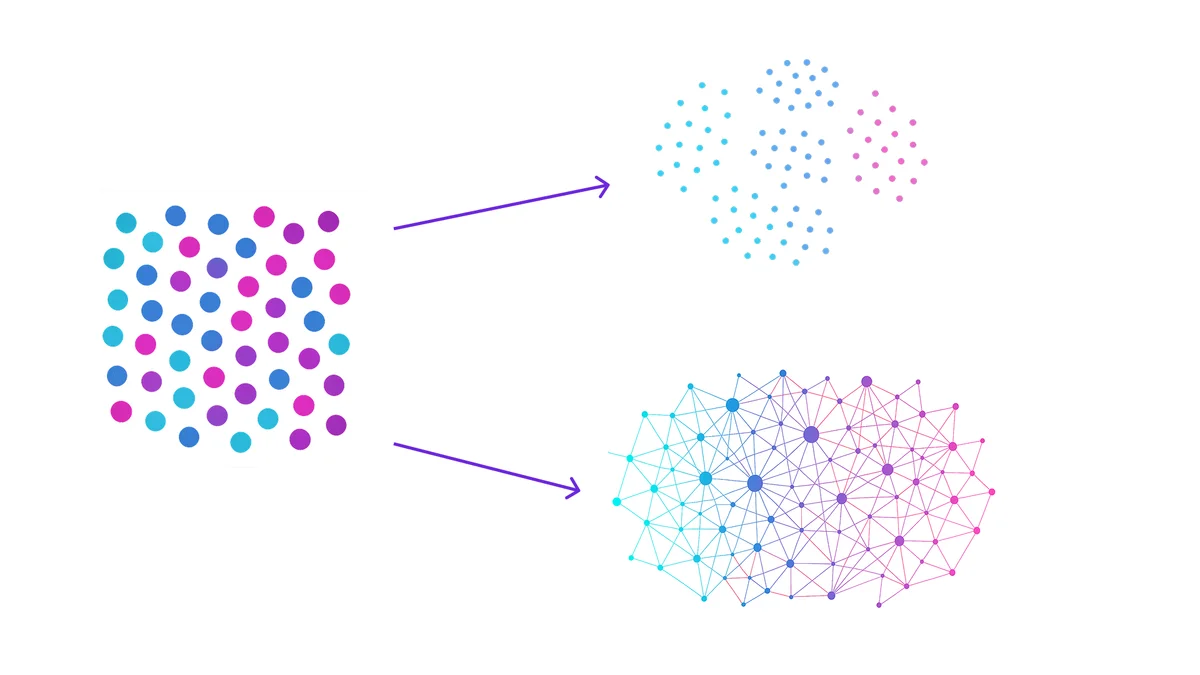
As AI becomes central to SaaS products, companies are discovering that the quality of AI analysis depends not just on the AI models themselves, but on how information is structured and accessed. While initial AI integration efforts focused on simply connecting LLMs to existing data stores, we’re now entering a more sophisticated phase where the data architecture itself determines analytical accuracy.
This evolution parallels what we’ve seen in traditional software development. Just as software architecture evolved from flat files to relational databases to microservices, AI data architecture is progressing from simple vector embeddings to semantic knowledge structures that better represent real-world information.
While vector databases have been instrumental in building the LLMs we use today, knowledge graphs fundamentally outperform them for complex AI analysis tasks, particularly when deep understanding of relationships between entities is critical. The underlying data architecture directly impacts the accuracy and reliability of AI-powered insights, with knowledge graphs providing a clear advantage for sophisticated analytical applications.
The Challenge: Beyond Simple Retrieval
Many SaaS companies are integrating AI into their products using a now-standard architecture combining LLMs with vector databases:
-
Data Processing Pipeline: Documents are chunked into 1-4KB segments, processed to remove noise, and embedded using models like OpenAI’s text-embedding-ada-002 or other embedding models
-
Retrieval Augmented Generation (RAG): When users query the system, a similarity search retrieves relevant chunks, which are then injected into the prompt context of an LLM like GPT-4 or Claude
-
Vector Database Infrastructure: Solutions like Pinecone, Weaviate, Chroma, or Postgres with pgvector extensions store these embeddings for efficient similarity search
-
Prompt Engineering Layer: Custom prompts instruct the LLM how to use the retrieved context to answer questions, often with techniques like few-shot examples
As companies move toward more sophisticated AI implementations, they’re discovering fundamental limitations in this approach for complex analytical tasks:
-
Accuracy Degradation: When analysis requires understanding connections between multiple pieces of information, statistical similarity fails to provide reliable pathways for inference
-
Context Fragmentation: As information is chunked for vector databases, the relationships between those chunks are lost, leading to incomplete or misleading context
-
Limited Validation: When insights need verifiable information trails (crucial for regulatory, legal, or financial analysis), vector similarity can’t provide a reliable chain of evidence
-
Information Silos: Complex systems need structured data exchange with clear relationship semantics that vector databases simply don’t provide
AI Agents: A Partial Solution With Inherent Limitations
To address accuracy issues, many organizations are deploying AI agents to improve their vector database-based systems. These agents use sophisticated prompting, chain-of-thought reasoning, and task decomposition to enhance analytical capabilities.
However, AI agents built on vector databases still inherit the fundamental limitations of their underlying data architecture:
-
Reliability Ceiling: Even the most sophisticated AI agent can’t reliably reason about relationships that aren’t explicitly represented in the data
-
Error Propagation: When agents make inferences based on statistically similar but contextually disconnected data, errors compound across reasoning steps
-
Limited Verification: Without explicit relationship structures, agent reasoning paths remain difficult to verify or audit
Vector database architecture is known to fundamentally break down when handling complex domain information like regulatory, medical and legal data/terms. This requires understanding intricate relationships, hierarchies, and cross-document context. The statistical similarity approach simply cannot capture the explicit semantic connections needed for reliable analysis.
Vector Databases: The Statistical Approach

Vector databases work by converting documents into numerical representations (embeddings) and finding statistical similarities. This approach has become standard for good reasons:
Strengths of Vector Databases
-
Performance: Vector databases excel at high-speed querying of massive document sets, often returning results in milliseconds
-
Simplicity: The architecture is relatively straightforward to implement with modern tools and APIs
-
Content Flexibility: They can handle any text content without pre-defined schemas or ontologies
-
Language Understanding: Vector embeddings enhance similarity based matches, finding relevant content even when keywords don’t match
-
Integration Ready: They work seamlessly with current LLM APIs through standard RAG patterns
Critical Limitations for Complex Analysis
Despite these strengths, vector databases have fundamental limitations when applied to analytical tasks:
-
No Explicit Relationships: Vector databases can’t natively represent connections between entities. They can find “similar” documents but don’t understand that regulation X amends regulation Y or that entity A owns entity B.
-
Context Loss: When chunking documents for embedding, the broader context is often lost. A paragraph about a regulation might be retrieved, but its connection to the legal framework it belongs to disappears.
-
Limited Reasoning: Statistical similarity ≠ logical semantic relationship. Vector similarity can’t capture causal, hierarchical, or temporal relationships that are crucial for accurate analysis.
-
Hallucination Vulnerability: LLMs paired with vector databases are still prone to hallucinations when they need to reason across multiple retrieved chunks that lack explicit connections. While the accuracy of LLMs does elevate with vector databases, it is limited due to the considerably fuzzy nature of similarity based on vectors.
-
Query Depth Ceiling: Complex analytical queries requiring multi-hop reasoning become exponentially less reliable as the number of “hops” increases
Knowledge Graphs: The Semantic Approach

Knowledge graphs fundamentally differ by explicitly representing relationships between entities:
-
Structured Relationships: Knowledge graphs store not just the nodes (entities) but the edges (relationships) between them. A regulation can be explicitly linked to industries it affects, previous versions it supersedes, and entities it regulates.
-
Contextual Integrity: By preserving the relationships between information pieces, knowledge graphs maintain the bigger picture that vector databases fragment.
-
Enhanced Reasoning: When an LLM queries a knowledge graph, it can follow logical paths through relationships rather than making statistical leaps that lead to inaccuracies.
-
Reduced Hallucinations: With explicit relationship data, LLMs have grounded information about how facts relate, dramatically reducing hallucinations when synthesizing information.
-
Evidence Trails: Knowledge graphs enable verifiable information paths, showing exactly how conclusions were derived from source data—critical for regulatory and compliance scenarios.
Research-Backed Superiority
Microsoft Research has validated the effectiveness of knowledge graph approaches with their GraphRAG system, which demonstrated significant improvements in accuracy for complex queries on narrative data. Their research (GraphRAG: Unlocking LLM discovery on narrative private data) shows that by structuring information as graphs rather than independent chunks, LLMs can better understand and reason about complex stories and information structures.
Traditional Challenges with Knowledge Graphs
Despite their analytical advantages, knowledge graphs have historically faced adoption barriers:
-
Implementation Complexity: Traditional knowledge graphs required specialized expertise in knowledge engineering and ontology design
-
Performance Overhead: Graph query operations can be computationally expensive and slower than vector similarity searches, especially at scale
-
Maintenance Cost: Keeping knowledge graphs updated and consistent traditionally required significant ongoing effort
-
Integration Difficulty: Connecting knowledge graphs with LLMs has required custom development and often multiple API calls, increasing latency and costs
-
Domain Adaptation: Adapting knowledge graphs to new domains traditionally required extensive schema redesign
These limitations explain why many companies opted for simpler vector database approaches despite their analytical shortcomings. Modern approaches address these traditional challenges through AI-powered automation of knowledge graph construction and maintenance.
Real-World Impact: Regulatory Intelligence Example
Consider monitoring global regulations:
Vector Database Approach:
- Store regulatory documents as embeddings
- When a new regulation appears, retrieve “similar” documents
- Ask the LLM to interpret connections between these documents
- The LLM must guess relationships, leading to potential errors in understanding regulatory impact
Knowledge Graph Approach:
- Extract entities (regulations, industries, requirements) and relationships (affects, supersedes, requires)
- When a new regulation appears, traverse actual relationship paths
- Identify all affected industries, conflicting regulations, and compliance requirements through explicit links
- The LLM works with verified relationship data, not statistical approximations
The Future of Enterprise AI Architecture
As AI moves from novelty to mission-critical infrastructure, the foundations we build upon matter more than ever. Vector databases played a crucial role in the initial wave of AI adoption, helping companies quickly integrate LLMs with their existing data. They remain valuable for specific use cases like basic content retrieval and simple similarity matching.
However, for enterprises building sophisticated analytical systems and true semantic search capabilities, knowledge graphs represent the necessary evolution in AI data architecture. Just as relational databases became the standard for transaction processing systems, knowledge graphs are emerging as the foundation for reliable AI analysis systems.
The companies that recognize this architectural shift early will build AI systems with deeper analytical capabilities, more reliable outputs, and sustainable competitive advantages in how they derive intelligence from their data.